0x00 基本信息
作者: o1hy@DAS
原文作者: Beatrice Perez, Mirco Musolesi, and Gianluca Stringhini
原文标题: You are your Metadata: Identification and Obfuscation of Social Media Users using Metadata Information
原文会议或期刊: ICWSM2018(交叉型学科会议,人文科学社交网络)
原文链接: https://www.ucl.ac.uk/~ucfamus/papers/icwsm18.pdf
论文主要内容: 讨论元数据与隐私,以及报保护元数据
0x01 文章解读
问题提出
通常,人们关心的多为内容的安全,而信息的元数据被认为是不那么重要的.用户也通常不会在意对元数据的保护.一些厂商甚至会去收集用户的元数据,并告知用户,这不会侵犯他们的个人隐私.文章中,讨论了元数据到底会不会侵犯一个人的隐私.以及该怎么保护这些元数据.
文章结构
第一部分
作者以推特数据为实验数据,通过构造不同的特征,并且用了三种不同的机器学习算法通过这些特征识别用户,来验证保护元数据的重要性.
第二部分
作者通过两种方法来混淆,隐藏元数据,然后重新进行检测.用来验证元数据能否被保护.
模型设计
检测模型
用户集合
$$U = {u_1,u_2,…,u_k,..,u_M}$$
每一个用户,都可以被一组特征标识.
$$X^{u_k} = {x^{u_k}_1,x^{u_k}_2,…,x^{u_k}_R}$$
所以可以认为,有M个用户,每一个用户都可以被唯一的特征锁标识,所以我们的目标就是在特征集合I中识别出具体的用户.
$$I = {i_1,i_2,…,i_M}$$
所以最后的识别公式为
$$P_I(u_k) = {p_{i_1}(u_k),p_{i_2}(u_k),…,p_{i_M}(u_k)}$$
识别的结果为:
$$max_{i_l}{p_{i_l}(u_k)}$$
本文认为,每一个用户都会有一组唯一的特征,所以可以根据这组特征来识别不同的用户.
元数据保护模型
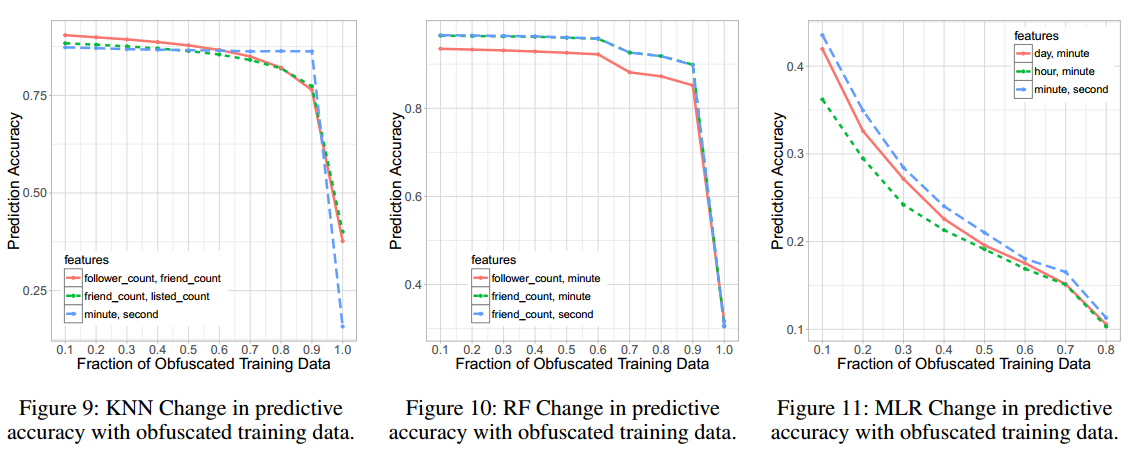
本文采用了两种方法混淆元数据,一种是: data anonymization ,另一种是: data randomization .文章主要使用了==data anonymization==的方式进行对元数据的混淆和检测.
data anonymization
数据匿名化是由其中列的值被分为不同的类别的过程中,并且每个读取是通过其相应的类别的索引代替。
data randomization
数据随机化是根据一些预定函数改变每列中的数据点的子集的值的技术。
简单的来讲,对于每一个账户,又会有一个用户创建时间(ACT),这个时间会的形式是 年:月:日:时:分:秒,例如:2001:3:20:12:21:30.通过数据匿名的方式,这个时间会变成:2001年三月份
实验数据
通过 Twitter Streaming Public API (Twitter, Inc. 2018) 随机的选取了 151,215,987条数据,涵盖了11,668,319个用户.但是最后的使用的用户集仅采用了发过的推文多于200的用户:5,412,693位用户.
实验步骤
用户识别
特征选取
对于一个账户而言,元数据的特征有很多.每一个账户的元数据包含了144个字段.这些字段提供的信息包括很多.所选择的特征是那些描述用户帐户并且不受用户直接控制的特征,但被排除的帐户ID除外,因为它被用作每个观察的基本事实(标签).
最后选择出的单个特征如下表.
| 特征 | 描述 |
|---|---|
| Account creation | 账户创建时间 |
| Favourites count | 用户标记⭐的数量 |
| Follower count | 用户的关注的人数 |
| Friend count | 朋友数量 |
| Geo enabled | (boolean)指示此帐户的推文是否已进行地理标记 |
| Listed count | 包含该帐户的公共列表的数量 |
| Post time stamp | 推文发送时间 |
| Statuses count | 账户发送的推文的数量 |
| Verified | 有没有被官方认证 |
| 文章中选择的特征包括:单一特征和不同的特征组合.在这些特征中有静态特征和动态特征 |
算法选择
文章选择了三种机器学习算法:随机森林,K邻近,逻辑回归.
随机森林选择了信息熵作为节点分割标准,K邻近选择欧氏距离作为具体计算方式.逻辑回归选择了limited-memory
每个分类器的内部参数的优化是作为现场最佳实践和实验结果的组合进行的
其中我们使用scikit-learn提供的交叉验证
通过将相同的特征或者特征组分别用这三种方法去训练,然后验证准确率.
结果
通过上一步证明,得到结论:元数据可以标识用户身份.并将扰乱元数据后,个人身份依然可以被识别出来.
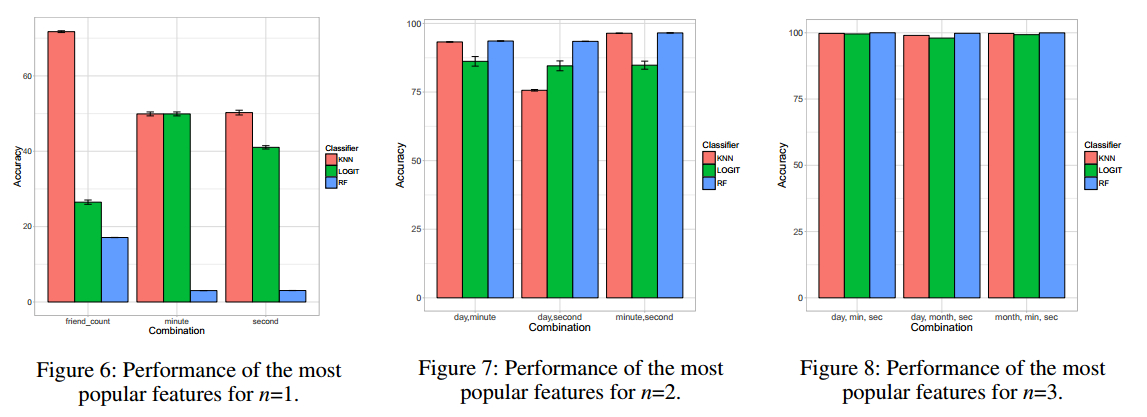
下面是文章在实验过程中,对于不同推文的各种特征选择的算法结果。
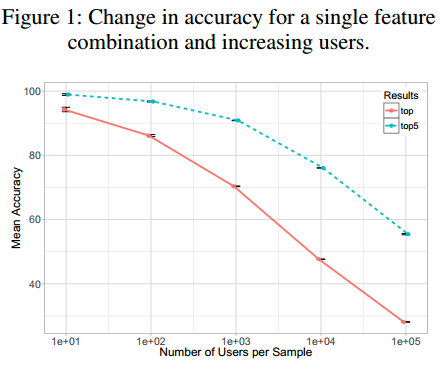
single feature combination 随着增加的用户
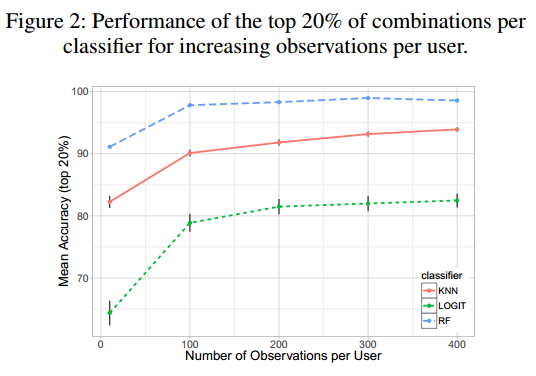
每个用户观察的推文数量
单一属性的熵

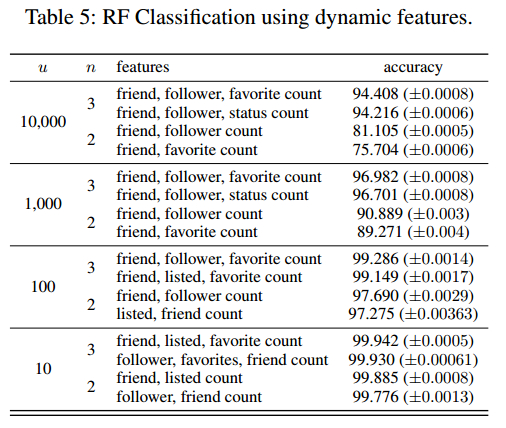
动态属性

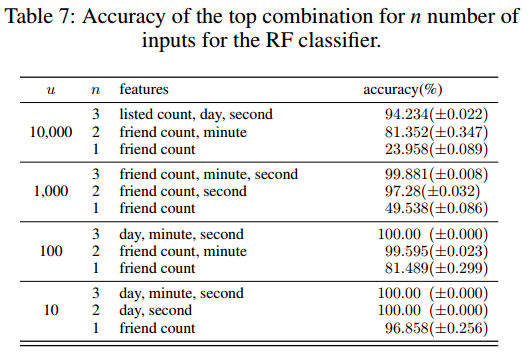
动静混合-特征


机器学习比较
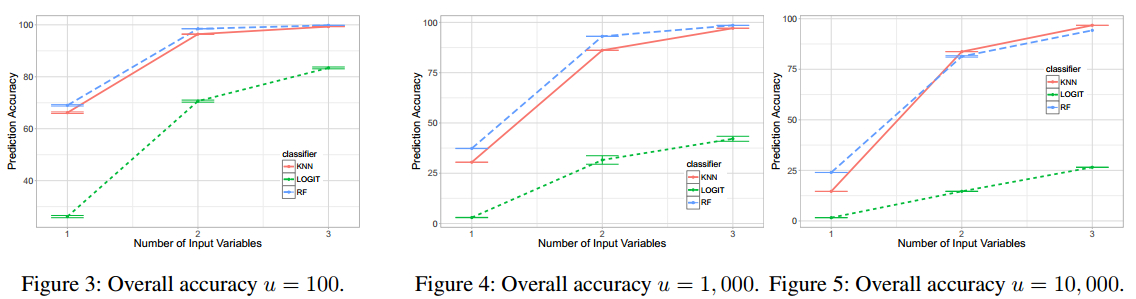
多特征结果
混淆后的检测
0x02 分析
-
本文有一个大的前提背景,就是,这个模型应用在黑客攻击时使用。所以关于 twiter的用户数量以及推文数量和获取的元数据的类型都是有一定范围的。
-
本文提出的观点可以用于不同社交系统间的使用.
-
动态特征到底对用户识别的贡献有多大影响;或者说,动态特征例如:用户的粉丝,是否真的可以作为用于区分用户身份的特征;或者如何操作。几个数量之间的变换或者很短时间内(1,2天)可以继续识别,假如过了一个月或者更久。
-
data anonymization 方式的扰乱数据,会创造出新的元数据,索引表.